












De “¿tenemos backup?” a resiliencia comprobable
El contexto 2025–2026: menos apagones “clásicos”, más incidentes complejos y ciber con alto impacto
- En data centers, la frecuencia y severidad de apagones reportados viene bajando, pero aumenta la complejidad (cadenas de terceros, red, software) y los ciberincidentes son de los más costosos. Es decir, menos fallos simples, más escenarios compuestos difíciles de diagnosticar y contener.
- En ciber, ~69% de organizaciones sufrió al menos un ataque de ransomware el último año (ligera baja vs. 75%), pero solo 10% logró recuperar >90% de la data; 57% recuperó <50%: la brecha es de recuperación, no solo de prevención. Además, crecen ataques de exfiltración (robo y extorsión) sin cifrado masivo.
Traducción operativa: hoy la diferencia entre “volvimos en horas” y “semanas perdidas” está en disponer de puntos de restauración limpios e inmutables y en tener RPO/RTO reales y probados, no en suposiciones.
Tres dolores recurrentes (y cómo los están resolviendo)
Dolor A — “Tenemos Microsoft 365, ¿no está ya respaldado?”
Riesgo: confundir disponibilidad del servicio con backup propio. El modelo de responsabilidad compartida deja al cliente la protección, retención y recuperación de sus datos; Microsoft recomienda copias regulares/terceros. “Versiones” o “legal hold” no sustituyen restauraciones masivas tras ransomware.
Qué funciona:
- Definir cobertura por workload (Exchange/SharePoint/OneDrive/Teams), retenciones y restores a escala (no solo por usuario). Documentar RPO/RTO y ensayar.
Dolor B — “El ransomware tocó también los backups”
Riesgo: repositorios mutables y credenciales expuestas permiten borrar o cifrar las copias.
Qué funciona:
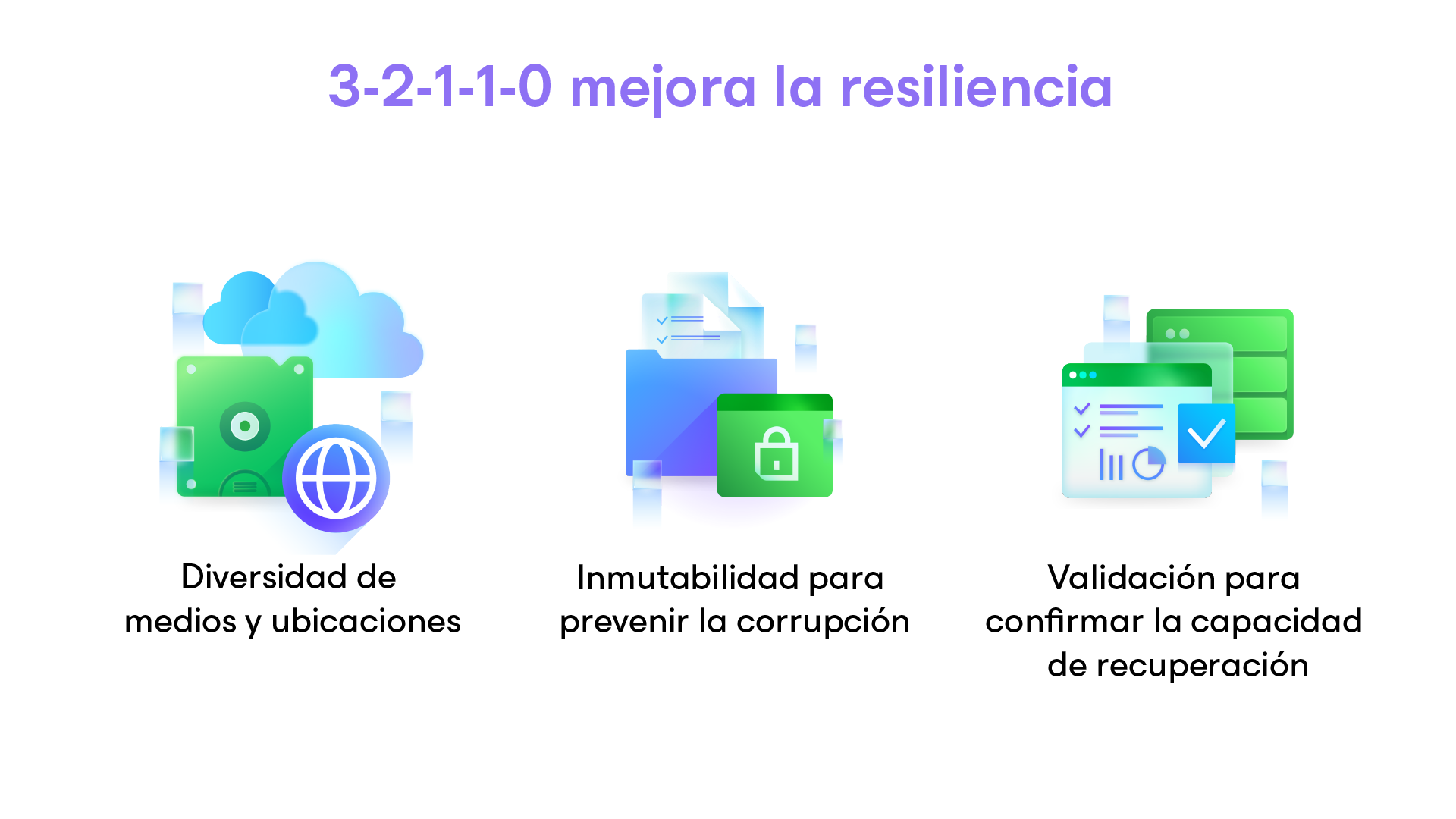
- Regla 3‑2‑1‑1‑0: 3 copias, 2 medios, 1 off‑site, 1 inmutable/air‑gap, 0 errores (verificados).
- Inmutabilidad con S3 Object Lock / WORM (o equivalentes Azure/GCP): se habilita al crear el bucket/contenedor, con versionado y retención adecuadamente configurados.
- Tener claro el “fine print”: object storage inmutable no se maneja como block; un mal diseño de retenciones/transformaciones encarece y puede ralentizar recuperaciones.
Dolor C — “El DR existía en papel, pero el RTO/RPO no cerró”
Riesgo: cifras teóricas que nunca se probaron.
Qué funciona: alinear RPO/RTO con impacto de negocio, separar
backup vs. retención legal vs. archivo y
orquestar pruebas periódicas de restauración con evidencia.
Lo mínimo viable de una estrategia moderna
- RPO/RTO por servicio (no global) y pruebas con evidencia.
- 3‑2‑1‑1‑0 con al menos una copia inmutable y verificación de cero errores.
- Si usas object storage, activar Object Lock/WORM y versioning al crear el bucket/contenedor; planificar retenciones y costes.
- Microsoft 365: cubrir Exchange/SharePoint/OneDrive/Teams con restores masivos; no depender de versiones/holds para incidentes a gran escala.
- Medir y mejorar: drills trimestrales y métricas de tiempo real de restore.
Preguntas clave que deberías poder contestar hoy
- ¿Dónde está tu copia inmutable (y cuánto dura la retención)?
- ¿Cuándo fue la última prueba de restauración completa (y cuánto tardaste)?
- ¿Puedes restaurar masivamente Microsoft 365 a un estado sano anterior sin tocar producción?
- ¿Tu 3‑2‑1 es realmente 3‑2‑1‑1‑0 (inmutable + verificación)?
Caso de éxito
Naturgy Argentina — DR más rápido y ciber‑resiliencia con Veeam
Naturgy Argentina (energía, >1.6M clientes en Buenos Aires) aceleró su digitalización y evidenció límites en su solución previa (gestión compleja, restores lentos, mayor riesgo ante ransomware).
Acciones tomadas: despliegue de Veeam Availability Suite para automatizar copias, manejar cargas (VMs/servidores físicos) desde una consola y mantener copias off‑site en un sitio de recuperación. La solución se instaló en días y hasta el staff junior pudo operar.
Resultados reportados:
- Menos tiempo de administración de backup y restauraciones más rápidas.
- Protección off‑site reforzada contra ciberataques.
- Menor curva de capacitación.
Lecciones trasladables: (1) consolidar en una plataforma con automatización y visibilidad integral, (2) disponer de copia fuera de sitio lista para DR y (3) simplificar la operación para que más personas puedan ejecutar restauraciones bajo presión
Ahora vamos con:
Nuestra Guía paso a paso (90 días) para pasar de “copias” a resiliencia demostrable
Días 0–30 — Visibilidad y riesgos
- Inventario de datos y servicios críticos y definición de RPO/RTO por servicio.
- Revisión de 365: mapear cobertura por workload y gap de restauraciones masivas.
- Auditoría de repositorios: ¿existe inmutabilidad (Object Lock/WORM) y off‑site real?
Días 31–60 — Diseño y ejecución
- Implementar/ajustar 3‑2‑1‑1‑0 (una copia inmutable, off‑site, verificación cero errores).
- Habilitar Object Lock/WORM (S3/Azure/GCP) y plan de retenciones (ojo a implicaciones de costos y borrado).
- Preparar runbooks de restore y pruebas por servicio (incluye 365 y cargas críticas).
Días 61–90 — Validación y evidencias
- Ejecutar drill de restauración end‑to‑end (producción simulada) y cronometrar tiempos.
- Documentar evidencias (capturas, logs, tiempos) y ajustar retenciones/infra según resultados.
- Presentar tablero a dirección: RPO/RTO alcanzados, postura de copia inmutable, brechas y próximos hitos.
Los ataques evolucionan, las arquitecturas se vuelven más complejas y los tiempos de negocio se acortan. La respuesta ya no es “tener backup”, sino poder restaurar limpio, rápido y con evidencia. Si priorizas 3‑2‑1‑1‑0 con al menos una copia inmutable, defines RPO/RTO por servicio, y pruebas tus restauraciones de forma periódica, reduces el riesgo real y conviertes tu plan de continuidad en una ventaja operativa.

